Um idioma surpreendente supera o inglês e o chinês nos testes de LLM, com base em um novo estudo acadêmico
Um novo estudo multilíngue que avalia como os modelos de idiomas grandes lidam com documentos longos produziu uma informação inesperada: O polonês, e não o inglês ou o chinês, apresenta a maior precisão quando as janelas de contexto chegam a 64.000 tokens ou mais. As descobertas vêm do benchmark OneRuler apresentado em um artigo do COLM 2025que testou 26 idiomas em tarefas de recuperação e agregação.
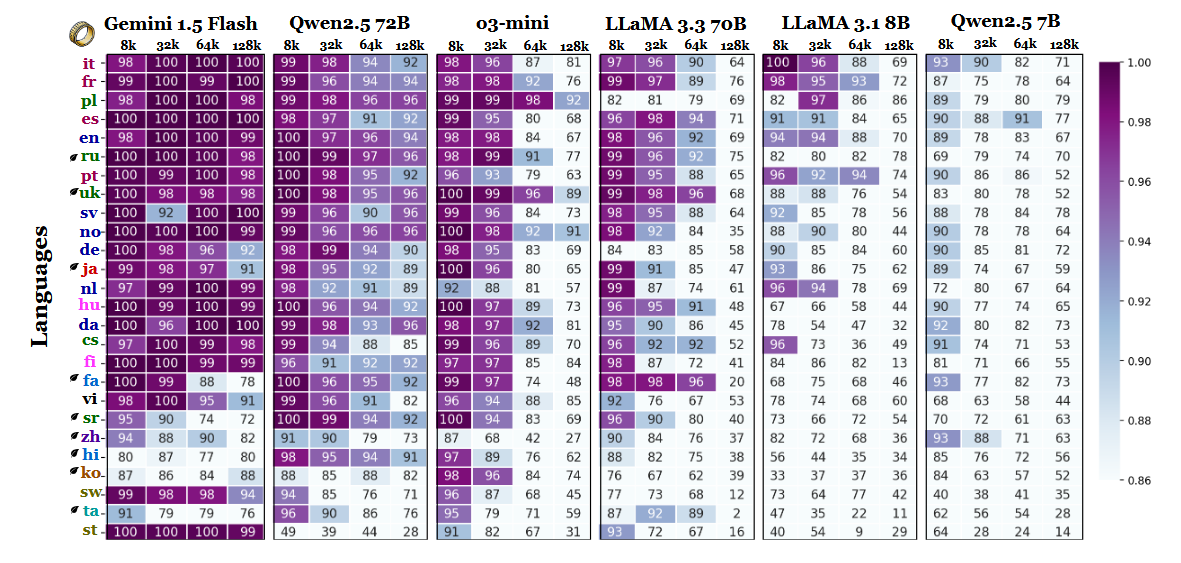
Os pesquisadores compararam a precisão do modelo em vários comprimentos de contexto e descobriram uma clara mudança quando as sequências se tornaram mais longas. De acordo com o gráfico de resultados (na página 6), o polonês lidera todos os idiomas com uma precisão média de 88% em escalas de contexto longo. O inglês cai para o sexto lugar e o chinês fica entre os quatro últimos.
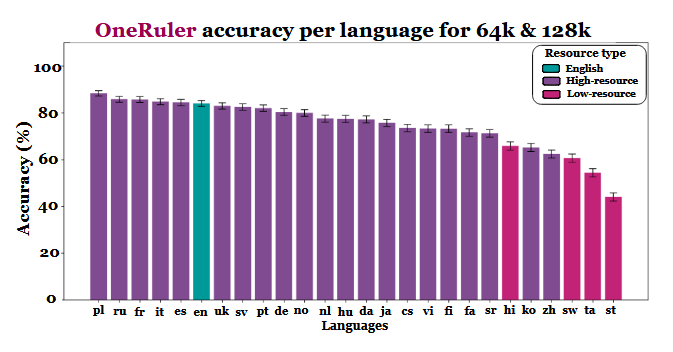
O estudo sugere que a disparidade pode estar ligada à eficiência da tokenização e às diferenças baseadas em scripts, em vez de simplesmente treinar o volume de dados. Os idiomas que usam escritas baseadas no latim, como o polonês, o francês e o espanhol, tiveram um desempenho consistentemente melhor do que aqueles que usam sistemas de escrita logográfica ou abugida. O chinês, o coreano, o tâmil e outros apresentaram apenas uma precisão moderada, mesmo em contextos mais curtos (e sua precisão se deteriorou ainda mais à medida que as sequências se tornaram mais longas). Esse total de 180 das classificações esperadas é interessante, pois a maioria dos LLMs amplamente implantados é treinada principalmente em conjuntos de dados com muito inglês. No entanto, os resultados do artigo indicam que, quando os modelos precisam pesquisar, recuperar ou resumir informações enterradas em documentos longos, os aspectos estruturais do idioma têm preferência sobre a prevalência do conjunto de dados.
Outras descobertas no benchmark também apóiam essa interpretação. A diferença de desempenho entre os idiomas mais fortes e os mais fracos cresce acentuadamente à medida que o contexto se expande - de 11% em 8.000 tokens para 34% em 128.000 tokens. Outro detalhe do estudo mostra como esses testes podem ser sensíveis a pequenas alterações nas instruções. Por exemplo, simplesmente permitir que o modelo responda "none" (nenhum) se uma cadeia de caracteres de destino estiver ausente fez com que a precisão em inglês caísse 32% com 128 mil tokens, como pode ser visto na página 2.
Embora o benchmark também compare as famílias de modelos, os resultados indicam que a avaliação de contexto longo não pode se basear somente em testes em inglês e que as generalizações de desempenho entre idiomas podem ser enganosas se os efeitos de script e tokenização forem ignorados. À medida que as janelas de contexto aumentam, as diferenças linguísticas se tornam mais importantes, e não menos, e a predominância do inglês nos benchmarks de LLM pode não ser mais representativa quando os comprimentos de sequência chegarem a dezenas de milhares.
Fonte(s)
Uma régua para medir todos eles: Benchmarking de modelos linguísticos multilíngues de contexto longo no COLM 2025
Imagem em destaque por Zulfugar Karimov em Unsplash

