CheckMag | Sem GPU, não há problema. Hospedar seu próprio LLM é infinitamente mais divertido do que as ofertas censuradas dos grandes players e funciona surpreendentemente bem.

O que realmente acontece com seus dados quando o senhor consulta uma IA é praticamente uma incógnita, mas o que quer que aconteça com eles, certamente não são mais seus.
Ao lado da imagem e de vídeo, se o senhor estiver interessado em fazer experiências com modelos de linguagem grande (LLM), mas não quiser entregar seus dados a grandes empresas de tecnologia, hospedar seu próprio modelo é surpreendentemente fácil e tem várias vantagens sobre os grandes players.
Em primeiro lugar, independentemente do que o senhor decida fazer com eles, todos os dados permanecem sob seu controle, o que, se o senhor não estiver interessado em entregar seus dados para Mechahitleré uma vantagem imediata. O senhor também pode usar praticamente qualquer modelo que desejar, seja ele Deepseek, Gemma2 ou GPT, com a vantagem adicional de poder usar versões que não restringem os tipos de consultas que o senhor faz.
O KoboldCPP é uma ferramenta de geração de texto de IA fácil de usar e de execução única, projetada para executar GGUF e GGML Large Language Models. Ele é compatível com GPU e CPU e pode atuar como um backend especializado para narração de histórias e bate-papo de IA. O KoboldCPP pode ser baixado do GitHub aqui e está disponível para Windows, Linux, Mac ou Docker.
A hospedagem em um contêiner torna trivial expor o LLM a todos os dispositivos da sua rede, e há modelos pré-construídos para as principais plataformas, incluindo Unraid e TrueNAS. O mesmo pode ser feito com outras instalações, desde que o senhor adicione as regras necessárias ao seu firewall.
Primeiros passos
Depois de decidir qual é a plataforma de sua preferência, o senhor precisará descobrir qual modelo usar. Hugging Face é o melhor lugar para procurar modelos, e eles precisam estar no formato GGUF.
Se estiver planejando hospedar cenários de D&D, o senhor definitivamente vai querer um modelo sem censura, caso contrário, o LLM acabará se recusando a prejudicar qualquer um dos personagens e poderá gerar resultados indesejáveis resultados indesejáveis.
Alguns modelos, como o Deepseek e Claudetêm uma propensão a "pensar", o que basicamente faz com que todo o processo de pensamento de sua consulta seja exibido. Isso pode ser bom com uma GPU fazendo o trabalho pesado, mas sem ela o processo fica consideravelmente mais lento. O senhor terá que experimentar modelos para encontrar um que funcione para você, mas o Gemma2 é um bom lugar para começar.
Localize a página de arquivos e copie o URL que vincula o arquivo GGUF. Muitos modelos têm vários tamanhos, portanto, o senhor precisará escolher um que se ajuste às limitações de sua memória RAM disponível.
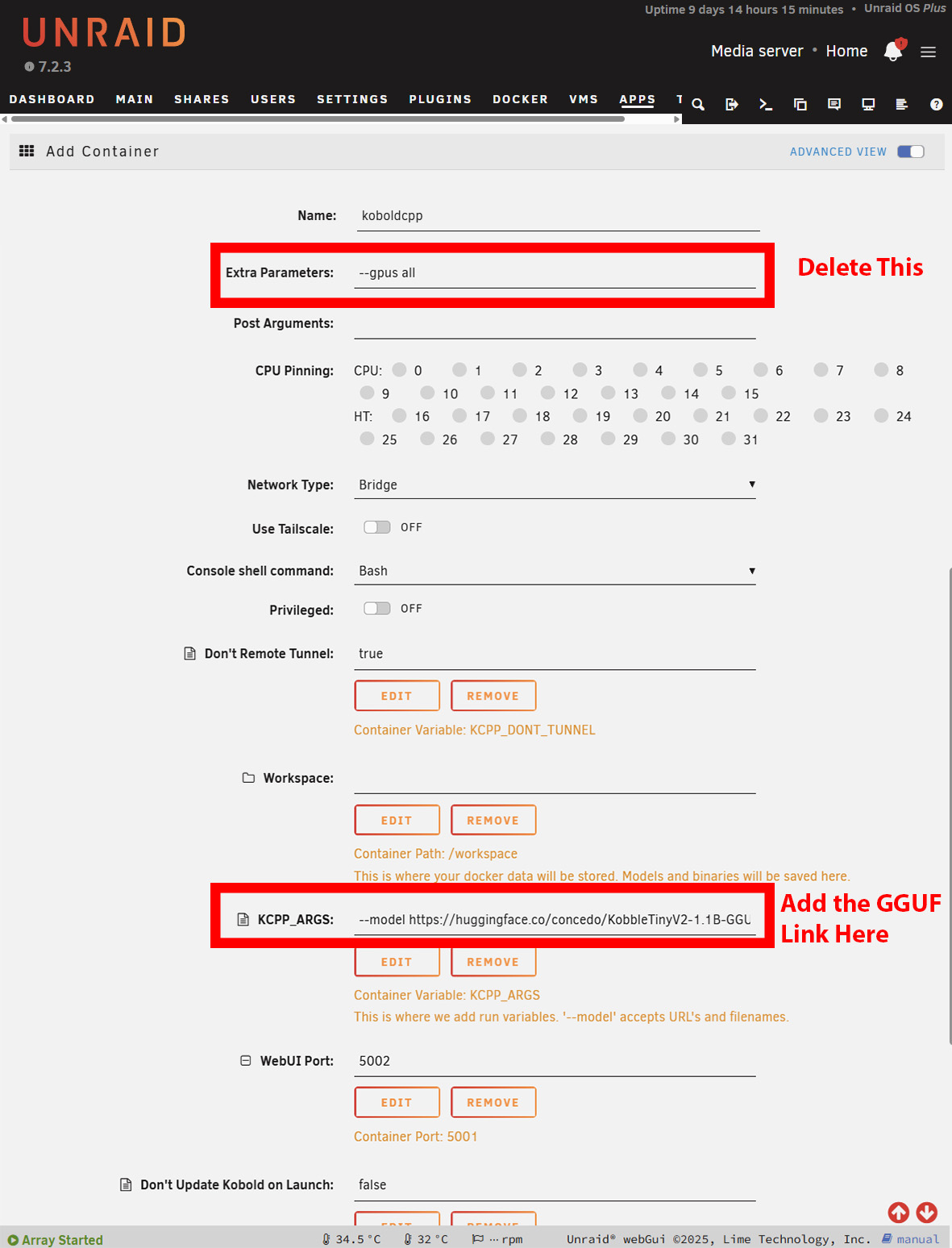
A instalação no Windows é praticamente a mesma. No entanto, o senhor precisará fazer o download da versão NoCUDA se estiver usando sem uma GPU. Pode demorar um pouco para iniciar, pois o KoboldCPP fará o download do modelo antes de apresentar a interface ao senhor. No Windows, isso é óbvio, mas no Unraid ou no TrueNAS, o senhor terá de abrir os registros para ver o progresso do download. No Unraid, talvez o senhor precise aumentar o armazenamento disponível dos contêineres do Docker o armazenamento disponível dos contêineres do Docker, dependendo do tamanho do modelo escolhido.
O KoboldCPP oferece quatro modos de interface diferentes, incluindo instrução, história, bate-papo e aventura.
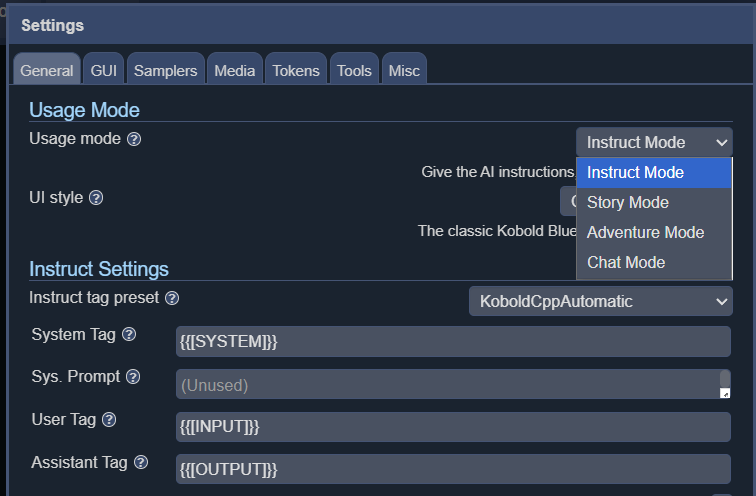
Embora não seja o mais rápido nem de longe, o texto é gerado um pouco mais lentamente do que a velocidade média de leitura. Perfeitamente útil para cenários de D&D quando executado em um AMD 5950x de 16 núcleos(disponível na Amazon) e provavelmente será mais rápido em CPUs mais modernas. Quanto mais núcleos o senhor puder usar, melhor, e uma quantidade decente de RAM permitirá a execução de modelos maiores, embora não haja problemas com 16 GB. O tamanho e o tipo de modelo também terão um impacto significativo na velocidade de geração, e a escolha de um modelo mais leve pode aumentar significativamente a velocidade geral.
Obviamente, para obter a melhor experiência, o ideal é executar modelos de idiomas grandes com uma GPU. No entanto, se quiser tentar hospedar o seu próprio modelo, ignorando as restrições ou implicações de privacidade de dados do ChatGPT, Claude ou Gemini, o senhor não precisa de nenhum hardware sofisticado para começar e ainda pode obter uma experiência decente.
Fonte(s)

