A tecnologia de IA da Universidade de Washington permite que os usuários de fones de ouvido escolham sons específicos para ouvir

Uma equipe liderada por pesquisadores de ciência da computação da Universidade de Washington (UofW) criou um software de IA para fones de ouvido que permite que os usuários selecionem sons específicos para ouvir. Diferentemente dos fones de ouvido com cancelamento de ruído que simplesmente filtram tudo, exceto as vozes, a nova rede neural permite que os usuários selecionem sons específicos, como o chilrear de um pássaro.
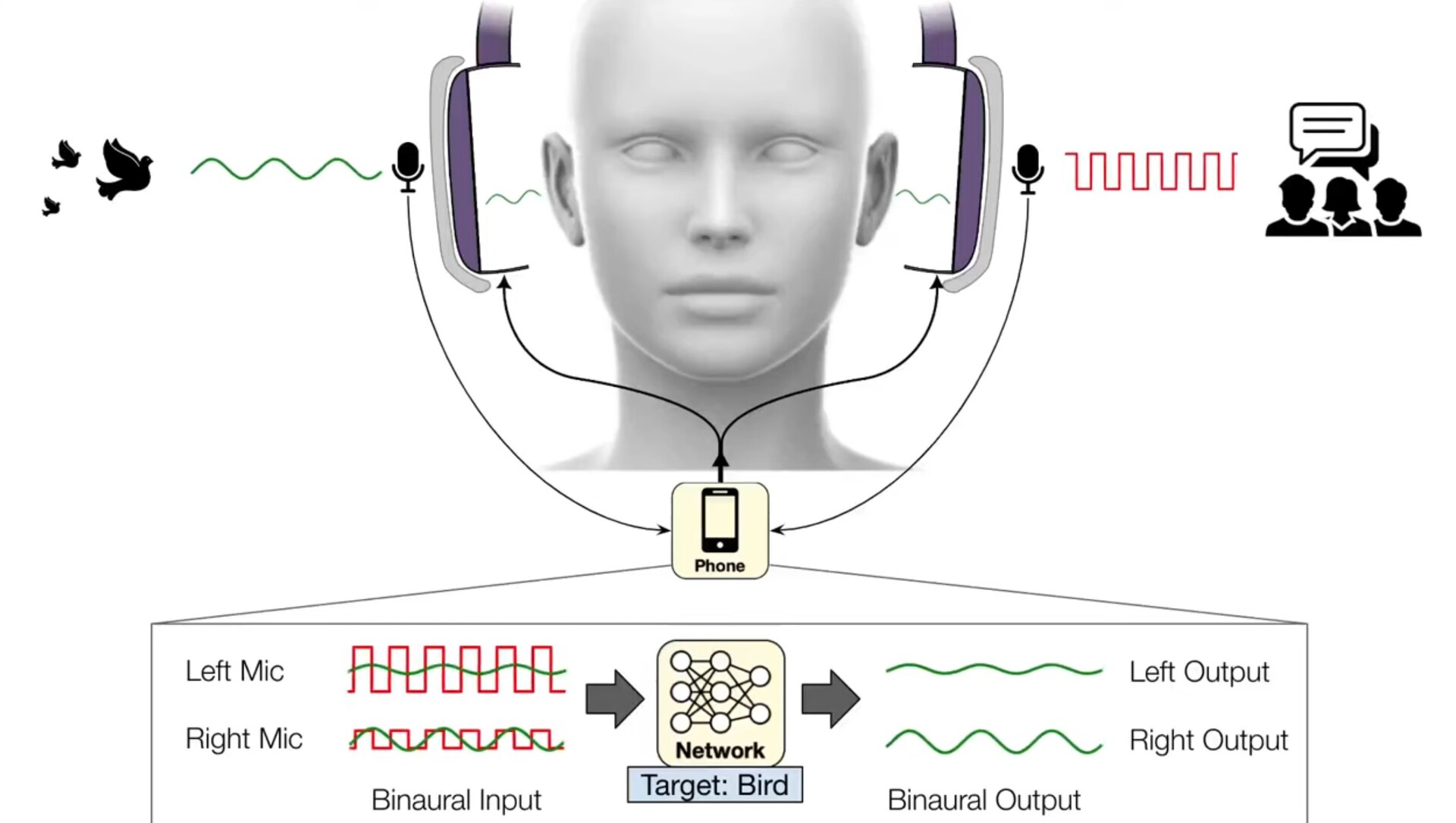
Fones de ouvido anteriores, como os fones de ouvido Sony INZONE(disponíveis na Amazon), usam DSEE Extreme, Speak-to-Chate AI DNNpara melhorar a qualidade da música e da fala e, ao mesmo tempo, permitir automaticamente que as vozes passem pelo cancelamento de ruído quando as conversas começam. O trabalho da UofW avança nesse sentido, permitindo que os ouvintes escolham entre 20 tipos diferentes de sons para ouvir, como o chilrear dos pássaros, o oceano, a batida da porta e a descarga do vaso sanitário, filtrando todo o resto. Chamado de audição semântica, isso permite que os usuários apreciem o chilrear dos pássaros em um parque sem ouvir pessoas conversando ou carros passando.
No momento, o aplicativo da UofW utiliza microfones binaurais para capturar a posição em tempo real dos sons externos antes de enviar os sons filtrados para os fones de ouvido. Como esse software é executado em smartphones, o aplicativo pode aproveitar CPUs mais potentes do que as encontradas nos fones de ouvido; no entanto, é apenas uma questão de tempo até que os fones de ouvido com cancelamento de ruído venham com a audição semântica integrada.


Fonte(s)
Universidade de Washington, ACMe Paul G. Allen School (YouTube)
9 de novembro de 2023
A nova tecnologia de fones de ouvido com cancelamento de ruído por IA permite que os usuários escolham os sons que querem ouvir
Stefan Milne
Notícias da UW
Quase todo mundo que já usou fones de ouvido com cancelamento de ruído sabe que ouvir o ruído certo no momento certo pode ser vital. Alguém pode querer apagar as buzinas dos carros quando estiver trabalhando em um ambiente fechado, mas não quando estiver caminhando em ruas movimentadas. No entanto, as pessoas não podem escolher quais sons seus fones de ouvido cancelam.
Agora, uma equipe liderada por pesquisadores da Universidade de Washington desenvolveu algoritmos de aprendizagem profunda que permitem aos usuários escolher quais sons serão filtrados pelos fones de ouvido em tempo real. A equipe está chamando o sistema de "audição semântica" Os fones de ouvido transmitem o áudio capturado para um smartphone conectado, que cancela todos os sons do ambiente. Por meio de comandos de voz ou de um aplicativo de smartphone, os usuários de fones de ouvido podem selecionar os sons que desejam incluir entre 20 classes, como sirenes, choro de bebês, fala, aspiradores de pó e chilreios de pássaros. Somente os sons selecionados serão reproduzidos pelos fones de ouvido.
A equipe apresentou suas descobertas em 1º de novembro na UIST '23 em São Francisco. No futuro, os pesquisadores planejam lançar uma versão comercial do sistema.
"Compreender o som de um pássaro e extraí-lo de todos os outros sons em um ambiente requer inteligência em tempo real que os fones de ouvido com cancelamento de ruído atuais não alcançaram", disse o autor sênior Shyam Gollakota, professor da UW na Paul G. Allen School of Computer Science & Engineering. "O desafio é que os sons que os usuários de fones de ouvido ouvem precisam estar sincronizados com seus sentidos visuais. O senhor não pode ouvir a voz de uma pessoa dois segundos depois de ela falar com o senhor. Isso significa que os algoritmos neurais devem processar os sons em menos de um centésimo de segundo."
Devido a essa limitação de tempo, o sistema auditivo semântico deve processar os sons em um dispositivo como um smartphone conectado, em vez de em servidores em nuvem mais robustos. Além disso, como os sons de diferentes direções chegam aos ouvidos das pessoas em momentos diferentes, o sistema deve preservar esses atrasos e outros sinais espaciais para que as pessoas ainda possam perceber de forma significativa os sons em seu ambiente.
Testado em ambientes como escritórios, ruas e parques, o sistema foi capaz de extrair sirenes, chilreios de pássaros, alarmes e outros sons-alvo, removendo todos os outros ruídos do mundo real. Quando 22 participantes avaliaram a saída de áudio do sistema para o som alvo, eles disseram que, em média, a qualidade melhorou em comparação com a gravação original. Em alguns casos, o sistema teve dificuldades para distinguir entre sons que compartilham muitas propriedades, como música vocal e fala humana. Os pesquisadores observam que o treinamento dos modelos com mais dados do mundo real pode melhorar esses resultados.
Outros coautores do artigo foram Bandhav Veluri e Malek Itani, ambos estudantes de doutorado da UW na Allen School; Justin Chan, que concluiu essa pesquisa como estudante de doutorado na Allen School e agora está na Carnegie Mellon University; e Takuya Yoshioka, diretor de pesquisa da AssemblyAI.
Para obter mais informações, entre em contato com [email protected].

